Si la programmation dite procédurale est constituée de procédures et
fonctions sans liens particuliers agissant sur des données dissociées
pouvant mener rapidement à des difficultés en cas de modification de la
structure des données, la programmation objet, pour sa part, tourne autour d'une unique entité : l'objet, offrant de nouvelles perspectives, et que je vous invite à découvrir de suite...
Attention !
Borland a longtemps employé le nom de Pascal Objet pour Delphi. Celui-ci a été récemment renommé langage Delphi. Nous n'aborderons pas dans ce tutoriel une approche spécifique à Delphi. Nous nous orienterons plus vers une approche générale du Pascal, tous compilateurs Pascal confondus sitôt que ceux-ci supportent la Programmation Orientée Objet, comme c'est le cas pour Turbo Pascal, Free Pascal, GNU Pascal... et bien sûr Delphi.
Borland a longtemps employé le nom de Pascal Objet pour Delphi. Celui-ci a été récemment renommé langage Delphi. Nous n'aborderons pas dans ce tutoriel une approche spécifique à Delphi. Nous nous orienterons plus vers une approche générale du Pascal, tous compilateurs Pascal confondus sitôt que ceux-ci supportent la Programmation Orientée Objet, comme c'est le cas pour Turbo Pascal, Free Pascal, GNU Pascal... et bien sûr Delphi.
1. Vue d'ensemble de la POO▲
Avant de rentrer plus avant dans le sujet qui nous intéresse, nous allons commencer par poser un certain nombre de bases.
1.1. L'objet▲
Il est impossible de parler de Programmation Orientée Objet sans parler d'objet, bien entendu.
Tâchons donc de donner une définition aussi complète que possible d'un objet.
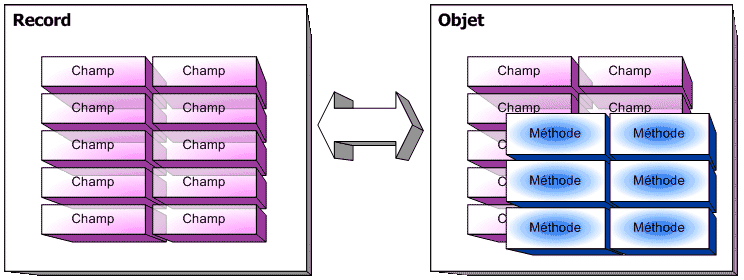
Un objet est avant tout une structure de données. Autrement, il s'agit d'une entité chargée de gérer des données, de les classer, et de les stocker sous une certaine forme. En cela, rien ne distingue un objet d'une quelconque autre structure de données. La principale différence vient du fait que l'objetregroupe les données et les moyens de traitement de ces données.
Un objet rassemble de fait deux éléments de la programmation procédurale.
Si nous résumons, un objet est donc un type servant à stocker des données dans des champs et à les gérer au travers des méthodes.
Si on se rapproche du Pascal, un objet n'est donc qu'une extension évoluée des enregistrements (type record) disposant de procédures et fonctions pour gérer les champs qu'il contient.
Un objet est avant tout une structure de données. Autrement, il s'agit d'une entité chargée de gérer des données, de les classer, et de les stocker sous une certaine forme. En cela, rien ne distingue un objet d'une quelconque autre structure de données. La principale différence vient du fait que l'objetregroupe les données et les moyens de traitement de ces données.
Un objet rassemble de fait deux éléments de la programmation procédurale.
-
Les champs :
Les champs sont à l'objet ce que les variables sont à un programme : ce sont eux qui ont en charge les données à gérer. Tout comme n'importe quelle autre variable, un champ peut posséder un type quelconque défini au préalable : nombre, caractère... ou même un type objet.
-
Les méthodes :
Les méthodes sont les éléments d'un objet qui servent d'interface entre les données et le programme. Sous ce nom obscur se cachent simplement des procédures ou fonctions destinées à traiter les données.
Si nous résumons, un objet est donc un type servant à stocker des données dans des champs et à les gérer au travers des méthodes.
Si on se rapproche du Pascal, un objet n'est donc qu'une extension évoluée des enregistrements (type record) disposant de procédures et fonctions pour gérer les champs qu'il contient.
On notera souvent les membres d'un objet Objet.Membre de façon à lever toute ambiguïté quant au propriétaire du membre considéré.
 |
1.2. Objet et classe▲
Avec la notion d'objet, il convient d'amener la notion de classe.
Cette notion de classe n'est apparue dans le langage Pascal
qu'avec l'avènement du langage Delphi et de sa nouvelle approche de la
Programmation Orientée Objet.
Elle est totalement absente du Pascal standard.
Ce que l'on a pu nommer jusqu'à présent objet est, pour Delphi, une classe d'objet. Il s'agit donc du type à proprement parler. L'objet en lui-même est une instance de classe, plus simplement un exemplaire d'une classe, sa représentation en mémoire.
Par conséquent, on déclare comme type une classe, et on déclare des variables de ce type appelées des objets.
Si cette distinction est à bien prendre en considération lors de la programmation en Delphi, elle peut toutefois être totalement ignorée avec la plupart des autres compilateurs Pascal. En effet, ceux-ci ne s'appuient que sur les notions d'objet et d'instance d'objet.
Nous adopterons par conséquent ici ce point de vue qui simplifie le vocabulaire et la compréhension.
On pourra remarquer que Free Pascal pour sa part définit une classe comme un "pointeur vers un objet ou un enregistrement".
Ce que l'on a pu nommer jusqu'à présent objet est, pour Delphi, une classe d'objet. Il s'agit donc du type à proprement parler. L'objet en lui-même est une instance de classe, plus simplement un exemplaire d'une classe, sa représentation en mémoire.
Par conséquent, on déclare comme type une classe, et on déclare des variables de ce type appelées des objets.
Si cette distinction est à bien prendre en considération lors de la programmation en Delphi, elle peut toutefois être totalement ignorée avec la plupart des autres compilateurs Pascal. En effet, ceux-ci ne s'appuient que sur les notions d'objet et d'instance d'objet.
Nous adopterons par conséquent ici ce point de vue qui simplifie le vocabulaire et la compréhension.
On pourra remarquer que Free Pascal pour sa part définit une classe comme un "pointeur vers un objet ou un enregistrement".
1.3. Les trois fondamentaux de la POO▲
La Programmation Orientée Objet est dirigée par trois fondamentaux qu'il convient de toujours garder à l'esprit : encapsulation, héritage et polymorphisme.
Houlà ! Inutile de fuir en voyant cela, car en fait, ils ne cachent que des choses relativement simples.
Nous allons tenter de les expliquer tout de suite.
1.3.1. Encapsulation▲
Derrière ce terme se cache le concept même de l'objet : réunir
sous la même entité les données et les moyens de les gérer, à savoir les
champs et les méthodes.
L'encapsulation introduit donc une nouvelle manière de gérer des données. Il ne s'agit plus de déclarer des données générales puis un ensemble de procédures et fonctions destinées à les gérer de manière séparée, mais bien de réunir le tout sous le couvert d'une seule et même entité.
Si l'encapsulation est déjà une réalité dans les langages procéduraux (comme le Pascal non objet par exemple) au travers des unités et autres librairies, il prend une toute nouvelle dimension avec l'objet.
En effet, sous ce nouveau concept se cache également un autre élément à prendre en compte : pouvoir masquer aux yeux d'un programmeur extérieur tous les rouages d'un objet et donc l'ensemble des procédures et fonctions destinées à la gestion interne de l'objet, auxquelles le programmeur final n'aura pas à avoir accès. L'encapsulation permet donc de masquer un certain nombre de champs et méthodes tout en laissant visibles d'autres champs et méthodes.
Nous verrons ceci un peu plus loin.
Pour conclure, l'encapsulation permet de garder une cohérence dans la gestion de l'objet, tout en assurant l'intégrité des données qui ne pourront être accédées qu'au travers des méthodes visibles.
L'encapsulation introduit donc une nouvelle manière de gérer des données. Il ne s'agit plus de déclarer des données générales puis un ensemble de procédures et fonctions destinées à les gérer de manière séparée, mais bien de réunir le tout sous le couvert d'une seule et même entité.
Si l'encapsulation est déjà une réalité dans les langages procéduraux (comme le Pascal non objet par exemple) au travers des unités et autres librairies, il prend une toute nouvelle dimension avec l'objet.
En effet, sous ce nouveau concept se cache également un autre élément à prendre en compte : pouvoir masquer aux yeux d'un programmeur extérieur tous les rouages d'un objet et donc l'ensemble des procédures et fonctions destinées à la gestion interne de l'objet, auxquelles le programmeur final n'aura pas à avoir accès. L'encapsulation permet donc de masquer un certain nombre de champs et méthodes tout en laissant visibles d'autres champs et méthodes.
Nous verrons ceci un peu plus loin.
Pour conclure, l'encapsulation permet de garder une cohérence dans la gestion de l'objet, tout en assurant l'intégrité des données qui ne pourront être accédées qu'au travers des méthodes visibles.
 |
1.3.2. Héritage▲
Si l'encapsulation pouvait se faire manuellement (grâce à la
définition d'une unité par exemple), il en va tout autrement de l'héritage.
Cette notion est celle qui s'explique le mieux au travers d'un exemple.
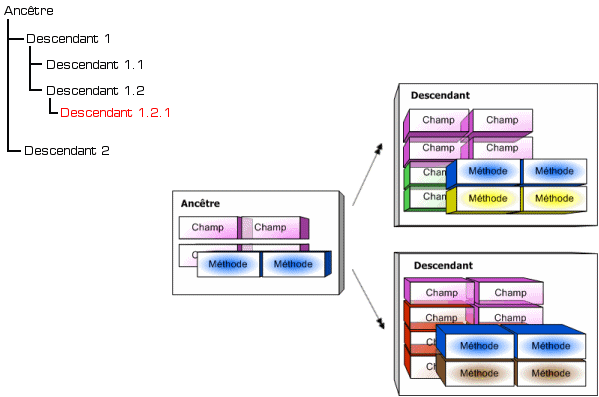
Considérons un objet Bâtiment.
Cet objet est pour le moins générique, et sa définition reste assez vague.
On peut toutefois lui associer divers champs, dont par exemple :
Ainsi, si l'on poursuit notre exemple, nous allons pouvoir créer un objet Maison. Ce nouvel objet est toujours considéré comme un Bâtiment, il possède donc toujours des murs, un toit, une porte, les champs Adresse ou Superficie et les méthodes destinées par exemple à Ouvrir le Bâtiment.
Toutefois, si notre nouvel objet est toujours un Bâtiment, il n'en reste pas moins qu'il s'agit d'une Maison. On peut donc lui adjoindre d'autres champs et méthodes, et par exemple :
Ce processus d'héritage peut bien sûr être répété. Autrement dit, il est tout à fait possible de déclarer à présent un descendant de Maison, développant sa spécialisation : un Chalet ou encore une Villa. Mais de la même manière, il n'y a pas de restrictions théoriques concernant le nombre de descendants pour un objet. Ainsi, pourquoi ne pas déclarer des objets Immeuble ou encore Usine dont l'ancêtre commun serait toujours Bâtiment.
Ce concept d'héritage ouvre donc la porte à un nouveau genre de programmation.
On notera qu'une fois qu'un champ ou une méthode sont définis, il ou elle le reste pour tous les descendants, quel que soit leur degré d'éloignement.
- les murs ;
- le toit ;
- une porte ;
- l'adresse ;
- la superficie.
- ouvrir le Bâtiment ;
- fermer le Bâtiment ;
- agrandir le Bâtiment.
Ainsi, si l'on poursuit notre exemple, nous allons pouvoir créer un objet Maison. Ce nouvel objet est toujours considéré comme un Bâtiment, il possède donc toujours des murs, un toit, une porte, les champs Adresse ou Superficie et les méthodes destinées par exemple à Ouvrir le Bâtiment.
Toutefois, si notre nouvel objet est toujours un Bâtiment, il n'en reste pas moins qu'il s'agit d'une Maison. On peut donc lui adjoindre d'autres champs et méthodes, et par exemple :
- nombre de fenêtres ;
- nombre d'étages ;
- nombre de pièces ;
- possède ou non un jardin ;
- possède une cave.
Ce processus d'héritage peut bien sûr être répété. Autrement dit, il est tout à fait possible de déclarer à présent un descendant de Maison, développant sa spécialisation : un Chalet ou encore une Villa. Mais de la même manière, il n'y a pas de restrictions théoriques concernant le nombre de descendants pour un objet. Ainsi, pourquoi ne pas déclarer des objets Immeuble ou encore Usine dont l'ancêtre commun serait toujours Bâtiment.
Ce concept d'héritage ouvre donc la porte à un nouveau genre de programmation.
On notera qu'une fois qu'un champ ou une méthode sont définis, il ou elle le reste pour tous les descendants, quel que soit leur degré d'éloignement.
 |
1.3.3. Polymorphisme▲
Le terme polymorphisme est certainement celui que l'on appréhende le plus.
Mais il ne faut pas s'arrêter à cela.
Afin de mieux le cerner, il suffit d'analyser la structure du mot : poly comme plusieurs et morphisme comme forme.
Le polymorphisme traite de la capacité de l'objet à posséder plusieurs formes.
Cette capacité dérive directement du principe d'héritage vu précédemment. En effet, comme on le sait déjà, un objet va hériter des champs et méthodes de ses ancêtres. Mais un objet garde toujours la capacité de pouvoir redéfinir une méthode afin de la réécrire, ou de la compléter.
On voit donc apparaître ici ce concept de polymorphisme : choisir en fonction des besoins quelle méthode ancêtre appeler, et ce au cours même de l'exécution. Le comportement de l'objet devient donc modifiable à volonté.
Le polymorphisme, en d'autres termes, est donc la capacité du système à choisir dynamiquement la méthode qui correspond au type réel de l'objet en cours. Ainsi, si l'on considère un objet Véhicule et ses descendants Bateau, Avion, Voiture possédant tous une méthode Avancer, le système appellera la fonction Avancer spécifique suivant que le véhicule est un Bateau, un Avion ou bien une Voiture.
Cette capacité dérive directement du principe d'héritage vu précédemment. En effet, comme on le sait déjà, un objet va hériter des champs et méthodes de ses ancêtres. Mais un objet garde toujours la capacité de pouvoir redéfinir une méthode afin de la réécrire, ou de la compléter.
On voit donc apparaître ici ce concept de polymorphisme : choisir en fonction des besoins quelle méthode ancêtre appeler, et ce au cours même de l'exécution. Le comportement de l'objet devient donc modifiable à volonté.
Le polymorphisme, en d'autres termes, est donc la capacité du système à choisir dynamiquement la méthode qui correspond au type réel de l'objet en cours. Ainsi, si l'on considère un objet Véhicule et ses descendants Bateau, Avion, Voiture possédant tous une méthode Avancer, le système appellera la fonction Avancer spécifique suivant que le véhicule est un Bateau, un Avion ou bien une Voiture.
Attention !
Le concept de polymorphisme ne doit pas être confondu avec celui d'héritage multiple. En effet, l'héritage multiple - non supporté par le Pascal standard - permet à un objet d'hériter des membres (champs et méthodes) de plusieurs objets à la fois, alors que le polymorphisme réside dans la capacité d'un objet à modifier son comportement propre et celui de ses descendants au cours de l'exécution.
Le concept de polymorphisme ne doit pas être confondu avec celui d'héritage multiple. En effet, l'héritage multiple - non supporté par le Pascal standard - permet à un objet d'hériter des membres (champs et méthodes) de plusieurs objets à la fois, alors que le polymorphisme réside dans la capacité d'un objet à modifier son comportement propre et celui de ses descendants au cours de l'exécution.
 |
2. Différents types de méthodes▲
Parmi les différentes méthodes d'un objet se distinguent deux types
de méthodes bien particulières et remplissant un rôle précis dans sa
gestion : les constructeurs et les destructeurs.
2.1. Constructeurs et destructeurs▲
2.1.1. Constructeurs▲
Comme leur nom l'indique, les constructeurs servent à construire l'objet en mémoire.
Un constructeur va donc se charger de mettre en place les données, d'associer les méthodes avec les champs et de créer le diagramme d'héritage de l'objet, autrement dit de mettre en place toutes les liaisons entre les ancêtres et les descendants.
Il faut savoir que s'il peut exister en mémoire plusieurs instances d'un même type objet, autrement dit plusieurs variables du même type, seule une copie des méthodes est conservée en mémoire, de sorte que chaque instance se réfère à la même zone mémoire en ce qui concerne les méthodes. Bien entendu, les champs sont distincts d'un objet à un autre. De fait, seules les données diffèrent d'une instance à une autre, la "machinerie" reste la même, ce qui permet de ne pas occuper inutilement la mémoire.
Certaines remarques sont à prendre en considération concernant les constructeurs.
Il faut savoir que s'il peut exister en mémoire plusieurs instances d'un même type objet, autrement dit plusieurs variables du même type, seule une copie des méthodes est conservée en mémoire, de sorte que chaque instance se réfère à la même zone mémoire en ce qui concerne les méthodes. Bien entendu, les champs sont distincts d'un objet à un autre. De fait, seules les données diffèrent d'une instance à une autre, la "machinerie" reste la même, ce qui permet de ne pas occuper inutilement la mémoire.
Certaines remarques sont à prendre en considération concernant les constructeurs.
- Un objet peut ne pas avoir de constructeur explicite. Dans ce cas, c'est le compilateur qui se charge de créer de manière statique les liens entre champs et méthodes.
- Un objet peut avoir plusieurs constructeurs : c'est l'utilisateur qui décidera du constructeur à appeler. La présence de constructeurs multiples peut sembler saugrenue de prime abord, leur rôle étant identique. Cependant, comme pour toute méthode, un constructeur peut être surchargé, et donc effectuer diverses actions en plus de la construction même de l'objet. On utilise ainsi généralement les constructeurs pour initialiser les champs de l'objet. À différentes initialisations peuvent donc correspondre différents constructeurs.
- S'il n'est pas nécessaire de fournir un constructeur pour un objet statique, il devient obligatoire en cas de gestion dynamique, car le diagramme d'héritage ne peut être construit de manière correcte que lors de l'exécution, et non lors de la compilation.
2.1.2. Destructeurs▲
Le destructeur est le pendant du constructeur : il se charge de détruire l'instance de l'objet.
La mémoire allouée pour le diagramme d'héritage est
libérée.
Certains compilateurs peuvent également se servir des destructeurs
pour éliminer de la mémoire le code correspondant aux méthodes d'un
type d'objet si plus aucune instance de cet objet ne réside en mémoire.
Là encore, différentes remarques doivent être gardées à l'esprit.
Là encore, différentes remarques doivent être gardées à l'esprit.
- Tout comme pour les constructeurs, un objet peut ne pas avoir de destructeur. Une fois encore, c'est le compilateur qui se chargera de la destruction statique de l'objet.
- Un objet peut posséder plusieurs destructeurs. Leur rôle commun reste identique, mais peut s'y ajouter la destruction de certaines variables internes pouvant différer d'un destructeur à l'autre. La plupart du temps, à un constructeur distinct est associé un destructeur distinct.
- En cas d'utilisation dynamique, un destructeur s'impose pour détruire le diagramme créé par le constructeur.
2.2. Pointeur interne▲
Très souvent, les objets sont utilisés de manière dynamique, et ne sont donc créés que lors de l'exécution.
Si les méthodes sont toujours communes aux instances d'un même type objet, il n'en est pas de même pour les données.
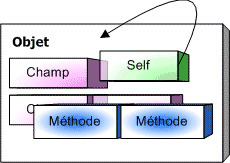
Il peut donc se révéler indispensable pour un objet de pouvoir se référencer lui-même. Pour cela, toute instance dispose d'un pointeur interne vers elle-même.
Ce pointeur peut prendre différentes appellations. En Pascal, il s'agira du pointeur Self.
D'autres langages pourront le nommer this, comme le C++...
Il peut donc se révéler indispensable pour un objet de pouvoir se référencer lui-même. Pour cela, toute instance dispose d'un pointeur interne vers elle-même.
Ce pointeur peut prendre différentes appellations. En Pascal, il s'agira du pointeur Self.
D'autres langages pourront le nommer this, comme le C++...
 |
2.3. Méthodes virtuelles et méthodes dynamiques▲
2.3.1. Méthodes virtuelles▲
2.3.1.1. Principe▲
Une méthode dite virtuelle n'a rien de fictif !
Il s'agit d'une méthode dont la résolution des liens est effectuée dynamiquement.
Voyons ce que cela signifie.
Comme nous le savons déjà, toute méthode est susceptible d'être surchargée dans un descendant, de manière à être écrasée ou complétée. Par conséquent, toute méthode surchargée donne lieu à création d'une nouvelle section de code, et donc à une nouvelle adresse en mémoire.
De plus, tout objet possède un lien vers la table des méthodes de ses ancêtres : le diagramme d'héritage. De fait, tout type objet est directement lié à ses types ancêtres. Autrement dit, si nous reprenons l'exemple du début, l'objet Maison peut être assimilé à un Bâtiment.
Considérons à présent la méthode Ouvrir d'un Bâtiment. Celle-ci consiste à ouvrir la porte principale.
À présent, surchargeons cette méthode pour l'objet Maison, de sorte que la méthode Ouvrir non seulement ouvre la porte principale, mais également les volets de notre Maison.
Déclarons maintenant une instance statique de Bâtiment, et appelons cette méthode Ouvrir. Lors de la création de l'exécutable, le compilateur va vérifier le type d'instance créé. Le compilateur lie alors notre appel à celui de Bâtiment.Ouvrir (la méthode Ouvrir de l'objet Bâtiment), en toute logique. Il ne se pose aucun problème.
Considérons à présent un autre exemple : déclarons une variable dynamique destinée, en principe, à recevoir un objet Bâtiment. Comme nous l'avons vu juste avant, l'objet Maison est compatible avec l'objet Bâtiment. Comme nous travaillons en dynamique, nous nous servons de pointeurs. De fait, je peux très bien décider, avec cette variable pointant vers un objet Bâtiment, de déclarer une instance de type Maison : le compilateur ne montrera aucune réticence.
Si nous résumons, nous avons donc une variable de type officiel pointeur vers Bâtiment et contenant en réalité une Maison.
Appelons alors notre méthode Ouvrir. Comme nous avons une Maison, il faut que l'on ouvre les volets. Or, si nous exécutons notre programme, les volets resteront clos. Que s'est-il passé ?
Lors de la création du programme, le compilateur s'est arrêté sur notre appel à Ouvrir. Ayant déclaré un objet Bâtiment, le compilateur ignore tout du comportement du programme lors de son exécution, et par conséquent ignore que la variable de type pointeur vers Bâtiment contiendra à l'exécution un objet Maison. De fait, il effectue une liaison vers Bâtiment.Ouvrir alors que nous utilisons une Maison !
La solution, vous l'aurez compris, réside dans l'utilisation des méthodes virtuelles. Grâce à celles-ci, la résolution des liens est effectuée dynamiquement, autrement dit lors de l'exécution. Ainsi, si nous déclarons notre méthode Ouvrir comme virtuelle, lors de la création du programme, le compilateur n'effectuera aucune liaison statique avant notre appel. Ce n'est que lors de l'exécution, au moment de l'appel, que la liaison va s'effectuer. Ainsi, au moment où l'on désirera appeler Ouvrir, notre programme va interroger son pointeur interne pour déterminer son type. Bien évidemment, cette fois-ci, il va détecter une instance de Maison, et l'appel se fera donc en direction de Maison.Ouvrir. Les volets s'ouvrent...
Vous aurez noté toute l'importance des méthodes virtuelles. D'une manière générale, sitôt qu'une méthode est susceptible d'être surchargée, il faut la déclarer comme virtuelle.
Comme nous le savons déjà, toute méthode est susceptible d'être surchargée dans un descendant, de manière à être écrasée ou complétée. Par conséquent, toute méthode surchargée donne lieu à création d'une nouvelle section de code, et donc à une nouvelle adresse en mémoire.
De plus, tout objet possède un lien vers la table des méthodes de ses ancêtres : le diagramme d'héritage. De fait, tout type objet est directement lié à ses types ancêtres. Autrement dit, si nous reprenons l'exemple du début, l'objet Maison peut être assimilé à un Bâtiment.
Considérons à présent la méthode Ouvrir d'un Bâtiment. Celle-ci consiste à ouvrir la porte principale.
À présent, surchargeons cette méthode pour l'objet Maison, de sorte que la méthode Ouvrir non seulement ouvre la porte principale, mais également les volets de notre Maison.
Déclarons maintenant une instance statique de Bâtiment, et appelons cette méthode Ouvrir. Lors de la création de l'exécutable, le compilateur va vérifier le type d'instance créé. Le compilateur lie alors notre appel à celui de Bâtiment.Ouvrir (la méthode Ouvrir de l'objet Bâtiment), en toute logique. Il ne se pose aucun problème.
Considérons à présent un autre exemple : déclarons une variable dynamique destinée, en principe, à recevoir un objet Bâtiment. Comme nous l'avons vu juste avant, l'objet Maison est compatible avec l'objet Bâtiment. Comme nous travaillons en dynamique, nous nous servons de pointeurs. De fait, je peux très bien décider, avec cette variable pointant vers un objet Bâtiment, de déclarer une instance de type Maison : le compilateur ne montrera aucune réticence.
Si nous résumons, nous avons donc une variable de type officiel pointeur vers Bâtiment et contenant en réalité une Maison.
Appelons alors notre méthode Ouvrir. Comme nous avons une Maison, il faut que l'on ouvre les volets. Or, si nous exécutons notre programme, les volets resteront clos. Que s'est-il passé ?
Lors de la création du programme, le compilateur s'est arrêté sur notre appel à Ouvrir. Ayant déclaré un objet Bâtiment, le compilateur ignore tout du comportement du programme lors de son exécution, et par conséquent ignore que la variable de type pointeur vers Bâtiment contiendra à l'exécution un objet Maison. De fait, il effectue une liaison vers Bâtiment.Ouvrir alors que nous utilisons une Maison !
La solution, vous l'aurez compris, réside dans l'utilisation des méthodes virtuelles. Grâce à celles-ci, la résolution des liens est effectuée dynamiquement, autrement dit lors de l'exécution. Ainsi, si nous déclarons notre méthode Ouvrir comme virtuelle, lors de la création du programme, le compilateur n'effectuera aucune liaison statique avant notre appel. Ce n'est que lors de l'exécution, au moment de l'appel, que la liaison va s'effectuer. Ainsi, au moment où l'on désirera appeler Ouvrir, notre programme va interroger son pointeur interne pour déterminer son type. Bien évidemment, cette fois-ci, il va détecter une instance de Maison, et l'appel se fera donc en direction de Maison.Ouvrir. Les volets s'ouvrent...
Vous aurez noté toute l'importance des méthodes virtuelles. D'une manière générale, sitôt qu'une méthode est susceptible d'être surchargée, il faut la déclarer comme virtuelle.
Attention !
Les constructeurs des objets ne seront jamais déclarés comme virtuels, car c'est toujours le bon constructeur qui est appelé. Le caractère virtuel est donc inutile et sera même signalé comme une erreur par le compilateur.
Par contre, les destructeurs seront toujours déclarés comme virtuels car souvent surchargés.
Il n'en est pas de même pour les classes qui elles peuvent s'appuyer sur le principe de constructeur virtuel. C'est notamment le cas de Delphi avec les références de classes à propos desquelles la documentation donne plus de précisions.
Vous pouvez aussi consulter les tutoriels suivants :
* Cours sur la POO de Frédéric Beaulieu ;
* Cours sur les métaclasses de Laurent Dardenne.
Les constructeurs des objets ne seront jamais déclarés comme virtuels, car c'est toujours le bon constructeur qui est appelé. Le caractère virtuel est donc inutile et sera même signalé comme une erreur par le compilateur.
Par contre, les destructeurs seront toujours déclarés comme virtuels car souvent surchargés.
Il n'en est pas de même pour les classes qui elles peuvent s'appuyer sur le principe de constructeur virtuel. C'est notamment le cas de Delphi avec les références de classes à propos desquelles la documentation donne plus de précisions.
Vous pouvez aussi consulter les tutoriels suivants :
* Cours sur la POO de Frédéric Beaulieu ;
* Cours sur les métaclasses de Laurent Dardenne.
2.3.1.2. Constructeurs et Table des Méthodes Virtuelles▲
Afin de pouvoir appeler la méthode appropriée au moment souhaité,
un objet doit s'appuyer sur une liste de ses méthodes virtuelles : la VMT ou Virtual Methods Table, la Table des Méthodes Virtuelles.
Cette table est mise en place par les constructeurs d'un objet.
Tout objet possède sa propre VMT, conservant toujours un lien avec la VMT de son ancêtre.
Lorsqu'un appel à une méthode virtuelle est effectué, l'objet recherche dans sa VMT s'il trouve la méthode recherchée. Si c'est le cas, alors il utilise l'adresse enregistrée et exécute la méthode. Sinon, il parcourt la VMT de son ancêtre direct et ainsi de suite jusqu'à l'ancêtre le plus éloigné dans la hiérarchie.
De même, lorsque qu'une méthode surchargée fait appel à la méthode ancêtre, alors une recherche est effectuée en partant cette fois-ci de la VMT du premier ancêtre.
La VMT est détruite par un destructeur lorsque celle-ci n'a plus lieu d'exister.
Tout objet possède sa propre VMT, conservant toujours un lien avec la VMT de son ancêtre.
Lorsqu'un appel à une méthode virtuelle est effectué, l'objet recherche dans sa VMT s'il trouve la méthode recherchée. Si c'est le cas, alors il utilise l'adresse enregistrée et exécute la méthode. Sinon, il parcourt la VMT de son ancêtre direct et ainsi de suite jusqu'à l'ancêtre le plus éloigné dans la hiérarchie.
De même, lorsque qu'une méthode surchargée fait appel à la méthode ancêtre, alors une recherche est effectuée en partant cette fois-ci de la VMT du premier ancêtre.
La VMT est détruite par un destructeur lorsque celle-ci n'a plus lieu d'exister.
Si jamais on utilise une méthode virtuelle sans avoir appelé au préalable un constructeur, le caractère virtuel ne sera pas pris en compte et les résultats seront imprévisibles.
2.3.2. Méthodes dynamiques▲
Après les méthodes virtuelles, on se demande ce que l'on a pu inventer de pire !
Rassurez-vous, rien du tout.
Les méthodes dynamiques ne sont en fait que des méthodes virtuelles.
Leur particularité réside dans le fait qu'elles sont indexées. Autrement dit, chaque méthode dynamique possède un numéro unique pour l'identifier.
Il convient de les comparer aux méthodes virtuelles :
Leur particularité réside dans le fait qu'elles sont indexées. Autrement dit, chaque méthode dynamique possède un numéro unique pour l'identifier.
Il convient de les comparer aux méthodes virtuelles :
- Avantage : les méthodes dynamiques consomment moins de mémoire ;
- Inconvénient : la gestion interne des méthodes dynamiques est plus complexe, et donc plus lente.
2.4. Méthodes abstraites▲
Une méthode abstraite est une méthode qu'il est nécessaire de surcharger.
Elle ne possède donc pas d'implémentation.
Ainsi, si on tente d'appeler une méthode abstraite, alors une erreur est déclenchée.
Bien entendu, il convient lors de la surcharge d'une telle méthode de ne pas faire appel à la méthode de l'ancêtre...
Les méthodes abstraites sont généralement utilisées lorsque l'on bâtit un squelette d'objet devant donner lieu à de multiples descendants devant tous posséder un comportement analogue. On pourra prendre notamment l'exemple de l'objet TStream et de tous ses descendants.
Bien entendu, il convient lors de la surcharge d'une telle méthode de ne pas faire appel à la méthode de l'ancêtre...
Les méthodes abstraites sont généralement utilisées lorsque l'on bâtit un squelette d'objet devant donner lieu à de multiples descendants devant tous posséder un comportement analogue. On pourra prendre notamment l'exemple de l'objet TStream et de tous ses descendants.
3. Visibilité▲
De par le principe de l'encapsulation, afin de pouvoir garantir la protection des données, il convient de pouvoir masquer certaines données et méthodes internes les gérant, et de pouvoir laisser visibles certaines autres devant servir à la gestion publique de l'objet. C'est le principe de la visibilité.3.1. Champs et méthodes publics▲
Comme leur nom l'indique, les champs et méthodes dits publics sont accessibles depuis tous les descendants et dans tous les modules : programme, unité...On peut considérer que les éléments publics n'ont pas de restriction particulière.
Les méthodes publiques sont communément appelées accesseurs : elles permettent d'accéder aux champs d'ordre privé.
Il existe des accesseurs en lecture, destinés à récupérer la valeur d'un champ, et des accesseurs en écriture destinés pour leur part à la modification d'un champ.
Il n'est pas nécessaire d'avoir un accesseur par champ privé, car ceux-ci peuvent n'être utilisés qu'à des fins internes.
Très souvent, les accesseurs en lecture verront leur nom commencer par Get quand leurs homologues en écriture verront le leur commencer par Set ou Put.
Aucun commentaire:
Enregistrer un commentaire